We introduce ExFunTube dataset, which consists of 10,136 funny short-form youtube videos. Videos are annotated with start and end timestamps and corresponding explanations. You can see an example of our ExFunTube dataset below, which has three funny moments!
Previous humorous video datasets are collected from limited domains, such as sitcoms or speeches. In speeches, there is a single speaker so visual cues are restricted to facial expressions or gestures. On the other hand, in sitcoms, fixed characters follow a predefined script on a constructed set, where visual cues are also resricted. For this reason, we collect multimodally funny short-form videos from YouTube!
How do we collect videos?
To verify multimodal fun, we devise a video filtering pipeline. We are inspired by other datasets that are proved as multimodal by comparing task performence between with and without visual cues. Therefore, we textualize videos, make GPT-3.5 explain why funny, and compare two results with and without visual information. Then, we select videos when two results are significantly different. With our pipeline, we can gather multimodally funny videos!
Why is our dataset important?
Short-form funny videos on social networks are gaining popularity. Thus, it becomes beneficial for AI models to understand them in that they can provide empathetic responses or recommend funny videos based on users’ sense of humor. Furthermore, videos in our dataset are annotated funny moments and corresponding explanations, which can be utilized to help models understand humor or evaluate model’s understanding of humor in depth!
Examples
Statistics
Funny Moments
There are 11,166 funny moments annotated. Out of 10,136 videos, 9,222 contain one funny moment, 798 contain two, and 116 contain three.
Explanations
Each moment is annotated with start and end timestamps and corresponding explanation. Thus, there are 11,166 explanations and they consist of 44.3 words on average.
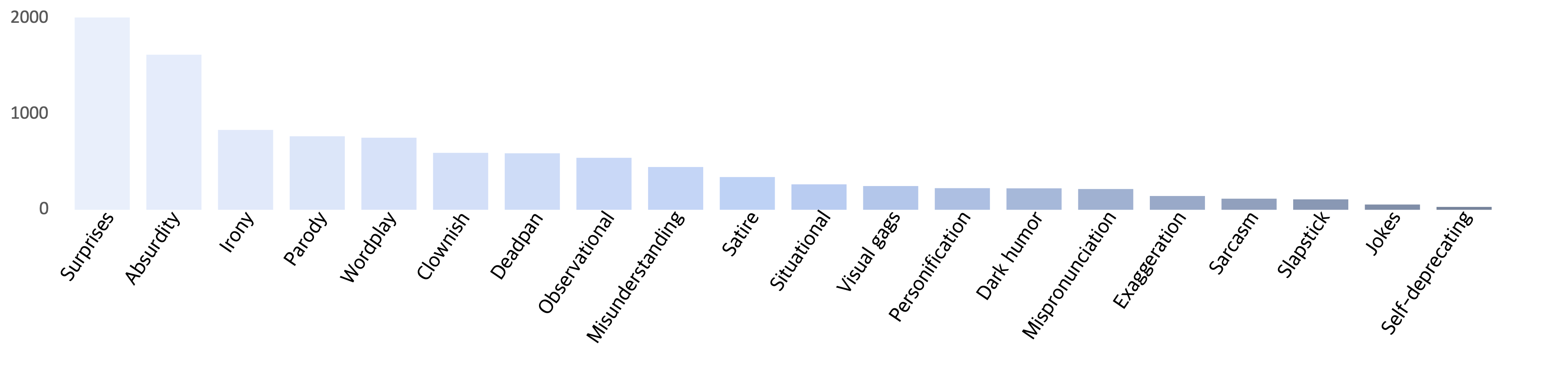
Categories
Thanks to GPT-3.5's in-context learing, we can effectively classify videos into 20 humor categories using annotated explanations. The results are shown below.
Download
We provide a json file of our dataset, consisting of youtube urls, timestamps of funny moments, and corresponding explanations. If you click the "Download Dataset" button below, you can download a json file of our dataset. For more information about our project, please refer to ExFunTube.
@inproceedings{
ko2023can,
title={Can Language Models Laugh at YouTube Short-form Videos?},
author={Dayoon Ko, Sangho Lee, Gunhee Kim},
booktitle={The 2023 Conference on Empirical Methods in Natural Language Processing},
year={2023}
}
Explanation: It's funny because the white dog is shown a dandelion then the dog eats the dandelion unexpectedly.
Moment 2.
Timestamp: 8s ~ 10s
Explanation: It's funny because the black and white dog is shown a dandelion and does the same thing as the white dog and eats the dandelion.
Moment 3.
Timestamp: 17s ~ 20s
Explanation: It's funny because the dog turns and notices the dandelion and goes over and eats the dandelion from the man's hand.
Example 2
Moment 1.
Timestamp: 2s ~ 6s
Explanation: It's funny to me because the implication is that lawnmower is sheep powered, because the sheep are pushing it, instead of horse powered. It's also weird to see sheep doing that.
Example 3
Moment 1.
Timestamp: 5s ~ 8s
Explanation: What is funny is that the man in the car puts his plain white icecream cone outside his window and when he brings it back inside the car you can see that it is covered with sprinkles. Another man had asked him if he thought is was raining today and he uses his sprinkled cone to show that it is "sprinkling". Making a joke of the two meanings for the word sprinkles creates the humor and the unexpected site of the icecream cone suddenly covered with candy sprinkles.
Example 4
Moment 1.
Timestamp: 1s ~ 5s
Explanation: You expect the bee to sting the man. It gives the man a high five instead and then puts his arm back.
Example 5
Moment 1.
Timestamp: 15s ~ 22s
Explanation: The goldfish is swimming around in his bowl saying, "I want to go to the aquarium." It is funny because he is a goldfish and he's already in a tank full of water.
Example 6
Moment 1.
Timestamp: 5s ~ 9s
Explanation: The video is funny because it features an animated clip featuring a man that is towing a luxury car while in the presence of its presumably wealthy owner that makes the sly comment in stating, "I had mixed reviews on the color. Some people say they like it, some people said they don't like it. I said well, what color is your Bugatti?" This remark is laughable because it implies that the man is rich and the person that is questioning the car color is not and is likely not in ownership of a Bugatti, so therefore, their opinion is irrelevant.
Moment 2.
Timestamp: 12s ~ 14s
Explanation: The video is also funny because the wealthy man that presumably owns the luxury car is left standing and laughing at his own remark as the tow truck driver speeds off and leaves him standing in the dust. Furthermore, it is comical to see that this man is left behind, especially on account of his projected arrogance.